
Wraz z rosnącą popularnością chłodzenia cieczą w centrach danych znaczenia nabierają systemy wczesnego wykrywania wycieków wody. Największą przeszkodą w upowszechnieniu chłodzenia płynami były dotąd obawy przed ryzykiem zalania infrastruktury IT. Nowoczesne rozwiązania minimalizują jednak to ryzyko m.in. poprzez ograniczanie objętości płynu w obiegu oraz wdrożenie mechanizmów szybkiej detekcji wycieku w kluczowych punktach instalacji. Inicjatywa Open Compute Project (OCP) opublikowała niedawno obszerny raport „Leak Detection and Intervention” (Wykrywanie wycieków i interwencja), który szczegółowo opisuje techniki i strategie wykrywania wycieków wody w centrach danych. Poniżej przedstawiamy przystępne podsumowanie najważniejszych wniosków z tego raportu – od aspektów technicznych systemów detekcji, przez rodzaje czujników i integrację z systemami zarządzania infrastrukturą, po najlepsze praktyki wdrożeniowe w różnych typach obiektów, ilustrowane przykładami.
Systemy detekcji wycieków – jak to działa?
System detekcji wycieku wody w centrum danych składa się zwykle z sieci czujników rozmieszczonych w newralgicznych miejscach oraz jednostek monitorujących, które natychmiast sygnalizują alarm w razie kontaktu sensora z cieczą. Czujniki rozmieszcza się w miejscach o podwyższonym ryzyku zalania – wzdłuż rurociągów chłodzenia, wokół złączek i zaworów, pod szafami serwerowymi z chłodzeniem wodnym, w tacach ociekowych pod urządzeniami HVAC itp. Po wykryciu wilgoci lub wody czujnik wysyła sygnał alarmowy do modułu kontrolera, który może uruchomić wielopoziomową reakcję: od lokalnej sygnalizacji dźwiękowej/świetlnej, przez powiadomienie personelu w systemie DCIM/BMS, aż po automatyczne działania ochronne. W rozwiązaniach najwyższej klasy alarm pojawiający się w systemie wykrywania wycieków jest zintegrowany z Data Center Infrastructure Management (DCIM) lub systemem zarządzania budynkiem (BMS), co pozwala natychmiast zaalarmować obsługę obiektu. Bardziej zaawansowane wdrożenia umożliwiają dodatkowo interwencję automatyczną – np. powiązanie alarmu z wyłączeniem pomp chłodziwa lub zamknięciem zaworów, tak aby możliwie szybko odciąć dopływ wody i zminimalizować skutki wycieku.

Na poziomie sprzętowym systemy detekcji mogą działać w układzie punkt-punkt (każdy czujnik podłączony osobno do modułu alarmowego) lub w konfiguracji ciągłego okablowania sensorycznego pokrywającego dużą strefę. Bardziej rozbudowane systemy liniowe potrafią precyzyjnie określić miejsce wycieku – mierząc zmianę sygnału wzdłuż kabla i obliczając odległość do punktu zalania. Dzięki temu w dużych obiektach można natychmiast zlokalizować źródło problemu, co znacznie skraca czas reakcji. Niezależnie od architektury, kluczowe jest aby system detekcji był zaprojektowany redundantnie i odpornie na uszkodzenia – w środowisku krytycznym, jakim jest centrum danych, pojedyncza awaria czujnika lub kontrolera nie może pozostawić „ślepej strefy” bez nadzoru.
Rodzaje stosowanych czujników wycieku
W raportowanej przez OCP analizie omówiono różne typy sensorów stosowanych do wykrywania wycieków. Czujniki te można podzielić według konstrukcji fizycznej oraz wykorzystywanej technologii pomiarowej:

Czujniki kablowe (ciągłe) – mają formę długiego kabla sensorycznego (tzw. taśmy lub „liny” wykrywania wycieku) rozwleczonego po chronionym obszarze. Taki kabel układa się np. wzdłuż podniesionej podłogi, wokół szaf rack z chłodzeniem wodnym czy w korytach pod przewodami – dzięki czemu jeden sensor może monitorować duży zasięg. W momencie kontaktu któregokolwiek odcinka kabla z wodą następuje przerwanie lub zmiana sygnału elektrycznego, co wyzwala alarm. Czujniki kablowe pozwalają wykryć wyciek w dowolnym miejscu na swojej długości, a bardziej zaawansowane modele są w stanie wskazać przybliżoną odległość do miejsca zalania. Typowym rozwiązaniem są kable działające na zasadzie rezystancyjnej – dwa przewody biegnące równolegle są odizolowane, a pojawienie się wody powoduje połączenie ich poprzez przewodzącą ciecz i spadek oporu, który rejestruje moduł alarmowy. Zaletą czujników kablowych jest możliwość pokrycia rozległego obszaru jednym czujnikiem; wadą – konieczność dokładnego ułożenia i zamocowania kabla oraz ryzyko uszkodzeń mechanicznych samej liny sensorowej (np. przy pracach serwisowych pod podłogą).

Czujniki punktowe – to nieduże sondy umieszczane w konkretnych lokalizacjach, typowo wszędzie tam, gdzie potencjalnie może pojawić się wyciek. Przykładowo instaluje się je na podłodze w najniższych punktach (gdzie spłynie woda), pod połączeniami kołnierzowymi i zaworami na rurach, wewnątrz tac ociekowych pod klimatyzatorami precyzyjnymi, a nawet wewnątrz obudów serwerów chłodzonych cieczą. Czujnik punktowy ma zwykle dwie odsłonięte elektrody – zetknięcie ich przez wodę powoduje spadek rezystancji i zadziałanie alarmu (jest to więc działanie rezystancyjne, analogiczne jak w przypadku kabla). Istnieją też punktowe sensory pojemnościowe, reagujące na zmiany wilgotności materiału lub otoczenia (np. wykorzystujące zjawisko zmiany pojemności kondensatora miernikowego pod wpływem zawilgocenia). Czujniki punktowe są proste, stosunkowo tanie i łatwe do zainstalowania nawet w trudnodostępnych miejscach. Jednak pojedynczy sensor obejmuje bardzo ograniczoną strefę, dlatego w praktyce stosuje się ich wiele – rozmieszczając siatkę detektorów pokrywających wszystkie krytyczne obszary. Systemy punktowe dobrze sprawdzają się np. w tackach ociekowych czy we wnętrzach urządzeń, gdzie precyzyjnie chcemy wiedzieć, czy woda dostała się do konkretnego komponentu.
Warto podkreślić, że oba powyższe podejścia często się uzupełniają. W dużej serwerowni kable detekcyjne mogą chronić całe ciągi infrastruktury (np. biegnąc wzdłuż magistrali chłodzenia), a dodatkowe czujniki punktowe pilnują miejsc o szczególnym ryzyku (jak okolice pomp, króćce przy wymiennikach, czy pod same serwery). W razie pojawienia się wody na podłodze lub nieszczelności w instalacji, system wykryje ją albo w sposób ciągły (kabel), albo punktowo – w obu przypadkach zapewniając szybkie zadziałanie alarmu.
Transmisja danych i integracja z systemami DCIM/BMS
Sam fakt wykrycia wycieku to dopiero początek – równie istotne jest niezawodne przekazanie informacji o alarmie do ludzi lub systemów, które mogą podjąć odpowiednie działania. Raport OCP podkreśla konieczność pełnej integracji detekcji wycieków z szerszym ekosystemem monitoringu infrastruktury centrum danych. W praktyce oznacza to połączenie systemu czujników z platformami DCIM (ang. Data Center Infrastructure Management) oraz/lub BMS (ang. Building Management System – system zarządzania budynkiem).
Na poziomie sprzętowym dostępne są różne technologie transmisji danych z czujników wycieku:
- Wyjścia stykowe/relay – najprostsza metoda integracji, gdzie moduł wykrywania wycieków wystawia sygnał bezpotencjałowy (przekaźnik) w momencie alarmu. Taki sygnał można bezpośrednio wprowadzić na wejście alarmowe kontrolera BMS lub jednostki DCIM. Rozwiązanie to jest bardzo niezawodne (działa nawet przy braku zasilania awaryjnego systemu IT), ale przekazuje tylko informację typu ON/OFF o alarmie, bez szczegółów.
- Integracja sieciowa (IP) – wiele nowoczesnych kontrolerów wycieków posiada port Ethernet i obsługuje protokoły komunikacyjne stosowane w centrach danych. Przykładowo system może wysłać zdarzenie SNMP trap do oprogramowania DCIM, udostępniać odczyt stanu czujników przez Modbus/TCP lub BACnet IP (typowe protokoły w BMS), a nawet komunikować się za pośrednictwem REST API. Taka integracja pozwala na bogatsze informacje – np. wskazanie konkretnego czujnika/części obiektu, która zgłosiła alarm, co ułatwia służbom technicznym szybkie namierzenie źródła wycieku.
- Bezprzewodowe czujniki IoT – w niektórych zastosowaniach (zwłaszcza na rozległym obszarze lub w trudno dostępnych miejscach) stosuje się bezprzewodowe sensory zalania. Mogą one komunikować się zdalnie przez WiFi, Bluetooth LE lub dedykowane sieci IoT (np. LoRaWAN) do bramki zbierającej dane. Rozwiązania tego typu są coraz powszechniejsze w niewielkich serwerowniach i na brzegowych lokalizacjach Edge, gdzie pełny system okablowania czujników byłby nieopłacalny. Minusem jest konieczność zapewnienia zasilania bateryjnego czujników i potencjalne opóźnienia w transmisji – w krytycznych instalacjach data center preferowane są wciąż czujniki przewodowe ze względu na ich deterministyczne działanie.
Niezależnie od wybranej technologii, niezbędne jest powiązanie alarmu o wycieku z procedurami operacyjnymi centrum danych. W praktyce oznacza to, że w oprogramowaniu DCIM/BMS powinny zostać zdefiniowane odpowiednie alerty i akcje – np. powiadomienie operatorów (SMS/emails), automatyczne zamknięcie zaworów elektrycznych, awaryjne wyłączenie zasilania zagrożonych urządzeń itp. Raport OCP zwraca uwagę, że w każdym przypadku wykrycia zalania sygnał alarmowy powinien natychmiast trafić do nadrzędnego systemu zarządzania infrastruktūrą, a organizacja musi zawczasu określić optymalną strategię reakcji. Tylko wtedy detekcja wycieku przekłada się na realne zwiększenie bezpieczeństwa – szybkie powiadomienie pozwala ograniczyć skutki zdarzenia do minimum.
Najlepsze praktyki wdrażania wykrywania wycieków
Ograniczanie ryzyka już na etapie projektu: Dokument OCP podkreśla, że skuteczna strategia zarządzania wyciekami obejmuje zarówno samą detekcję, jak i działania prewencyjne (zapobieganie) oraz ochronne (ograniczanie skutków). Dlatego zaleca się, by projektując układ chłodzenia cieczą stosować komponenty wysokiej jakości (uszczelnienia, armatura, złącza) oraz zapewnić ich poprawny montaż i konserwację – tak, aby zmniejszyć prawdopodobieństwo powstania nieszczelności. Ponadto infrastruktura powinna być podzielona na możliwie małe sekcje – ograniczenie objętości płynu w poszczególnych obiegach sprawi, że ewentualny wyciek będzie niewielki i łatwiejszy do opanowania. Stosuje się np. lokalne moduły chłodnicze (CDU – Coolant Distribution Unit) obsługujące tylko kilka szaf zamiast jednego dużego obiegu dla całej sali, dzięki czemu wyciek wpływa tylko na mały fragment systemu.
Instalacja fizyczna i rozmieszczenie czujników: Rurociągi z cieczą należy prowadzić z myślą o tym, aby ewentualna nieszczelność wyrządziła minimalne szkody. Standardy branżowe (np. ASHRAE) zalecają, by rurociągi z chłodziwem prowadzić nad alejkami serwisowymi, a nie bezpośrednio nad sprzętem IT, oraz aby pod wszystkimi potencjalnymi punktami kapania instalować korytka ociekowe (drip trays) wyposażone w czujniki wycieku i odprowadzenie płynu. W tradycyjnych centrach danych z podniesioną podłogą okablowanie hydrauliczne najlepiej prowadzić pod podłogą lub nisko przy niej – wtedy ewentualny wyciek skapuje od razu na podłoże, skąd może zostać wykryty i zatrzymany, zanim uniesie się do poziomu elektroniki. Z kolei w obiektach bez podłogi technicznej (typu slab floor) praktyką jest prowadzenie rur nad sufitem lub wysoko pod stropem, obowiązkowo z tacami ociekowymi pod każdą złączką. W tacach tych umieszcza się czujniki, które natychmiast wykryją nawet niewielką sączącą się ciecz. Ważne jest również odpowiednie rozmieszczenie czujników pod samymi szafami IT – zwykle montuje się sensory pod każdym zestawem chłodnic (np. pod chłodnicami drzwiowymi RDC czy modułami chłodzenia bezpośredniego do układów CPU/GPU). Dobrym zwyczajem jest też umieszczanie czujników na podłodze w każdym ciągu (rzędzie) racków z chłodzeniem wodnym, aby wykryć wodę rozlaną poza tacami.
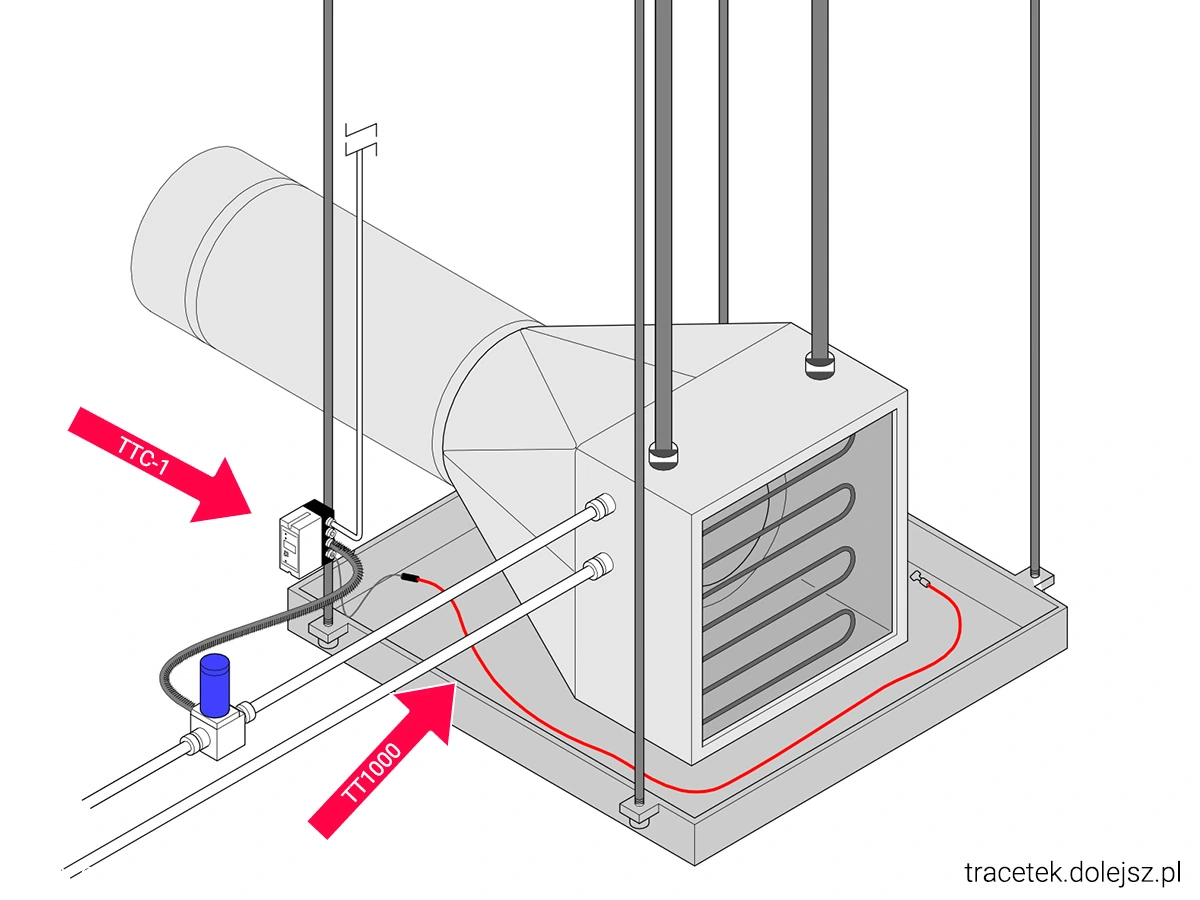
Integracja detekcji z mechanizmami automatyki: Jak wspomniano wcześniej, najlepsze wyniki daje powiązanie systemu wykrywania wycieków z automatyczną interwencją. Przykładowo, OCP opisuje wdrożenia, w których sygnał z czujników wycieków jest bezpośrednio podłączony do układu sterowania pompami lub zaworami – tak by w razie alarmu układ automatycznie zatrzymał cyrkulację płynu w zagrożonym obwodzie. Takie rozwiązanie pozwala niemal od razu „zamknąć” wyciekający odcinek i zredukować straty (zarówno utratę cennego chłodziwa, jak i zasięg zalania sprzętu). Innym mechanizmem ochronnym jest implementacja redundancji – np. podwójnych przewodów (tak, by w razie awarii jednego, chłodzenie odbywało się drugim), czy równoległych zaworów odcinających. OCP zwraca uwagę, że projektanci powinni zapewnić możliwość serwisowania układu chłodzenia bez narażania ciągłości pracy (np. wymiana uszkodzonego węża czy czujnika nie powinna wymuszać długiego przestoju).
Testowanie i konserwacja: Nie można pominąć kwestii utrzymania systemu detekcji w sprawności. Najlepsze praktyki obejmują regularne testy czujników (np. kontrolowane zwilżenie kabla sensorycznego lub zadziałanie czujnika punktowego, aby sprawdzić czy alarm generuje się poprawnie i dociera do systemu DCIM/BMS). Operatorzy powinni włączyć sprawdzanie systemu wycieków do okresowych przeglądów infrastruktury. Ważna jest też konserwacja prewencyjna – np. czyszczenie czujników (zakurzone czy pokryte zanieczyszczeniami mogą reagować wolniej lub generować fałszywe alarmy) oraz wymiana zużytych elementów (uszczelek, kształtek) zanim dojdzie do rozszczelnienia. OCP zaleca, by jasno zdefiniować procedury postępowania na wypadek wykrycia wycieku – personel powinien wiedzieć, gdzie odciąć dopływ wody, jak zabezpieczyć zasilanie urządzeń i jak szybko usuwać skutki zalania. Organizacje, które regularnie szkolą załogę z procedur awaryjnych, zdecydowanie lepiej radzą sobie z incydentami tego typu.
Powyższe ogólne dobre praktyki warto przełożyć na konkretne scenariusze, ponieważ różne typy centrów danych (modułowe, hiperskalowe, brzegowe) stawiają nieco odmienne wymagania co do systemów wykrywania wycieków.
Centra danych modułowe
Modułowe centra danych (np. kontenery lub prefabrykowane moduły IT) charakteryzują się małą kubaturą i wysoką gęstością upakowania infrastruktury. W takich warunkach nawet niewielki wyciek może bardzo szybko objąć znaczną część urządzeń. Dlatego w centrach modułowych zaleca się szczególnie agresywne podejście do detekcji – czujniki powinny pokrywać praktycznie całą powierzchnię podłogi modułu oraz przestrzeń pod podestami montażowymi dla serwerów. Często stosuje się tutaj kompletne wykładziny sensoryczne lub siatkę kabli detekcyjnych pokrywających dno modułu, tak by żadna kropla wody nie mogła pozostać niewykryta. Ponadto moduły te są fabrycznie wyposażane w systemy zarządzania infrastrukturą, więc integracja z lokalnym kontrolerem BMS odbywa się już na etapie produkcji. W praktyce moduł przychodzi do klienta z gotowym układem wykrywania wycieków zintegrowanym z kontrolerem – rolą operatora jest jedynie podłączyć moduł do nadrzędnego systemu monitoringu obiektu. OCP zwraca uwagę, że modułowe data center mogą dzięki temu osiągnąć wysoki poziom bezpieczeństwa – z racji małej skali łatwo jest fizycznie odseparować strefy mokre od suchych (np. prowadzić rurociągi wyłącznie w wydzielonych kanałach) oraz przewidzieć ukierunkowane odprowadzenie cieczy z ewentualnego przecieku (choćby do zbiornika awaryjnego pod podłogą). W modułach często dodaje się również mechaniczne zabezpieczenia, jak podniesione krawędzie progowe zapobiegające wylewaniu się wody poza kontener, co w połączeniu z czujnikami daje czas na reakcję zanim wyciek wydostanie się na zewnątrz.
Hiperskalowe centra danych
Hiperskalowe obiekty należące do gigantów technologicznych (takich jak centra danych firm Meta, Google, Microsoft itp.) coraz śmielej sięgają po chłodzenie cieczą, zwłaszcza na potrzeby gęstych klastrów AI/ML i HPC. W ich przypadku skala jest największym wyzwaniem – setki lub tysiące szaf rack z chłodzeniem bezpośrednim oznaczają rozległą sieć rurociągów i ogromną liczbę potencjalnych punktów nieszczelności. Z tego powodu najlepsze praktyki dla hiperskali obejmują zaprojektowanie systemu wykrywania wycieków w sposób skalowalny i segmentowalny. Stosuje się podział na strefy detekcji – np. każda hala podzielona jest na sekcje z osobnymi pętlami czujników kablowych w podłodze i osobnymi modułami alarmowymi, tak aby alarm precyzyjnie wskazywał dotkniętą strefę. Duzi operatorzy inwestują też w rozwiązania lokalizujące wyciek, żeby załoga nie musiała przeczesywać tysięcy metrów kwadratowych – przykładowo kable sensoryczne z funkcją pomiaru miejsca zalania (podające odległość w metrach) są wpinane w system DCIM, który na mapie hali pokazuje przybliżoną lokalizację problemu. Hiperskalowe centra danych często buduje się jako obiekty slab floor (bez podniesionej podłogi), więc standardem jest prowadzenie rur z chłodziwem nad sufitem – zgodnie z zaleceniami branżowymi, nad głównymi przejściami serwisowymi, z tacami ociekowymi i czujnikami pod każdą łączeniem. Takie podejście, połączone z systemami monitorowania, pozwala bezpiecznie korzystać z rurociągów nad sprzętem, co potwierdzają doświadczenia operatorów. Ważnym elementem w hiperskali jest też integracja z automatycznymi systemami orchestration – np. gdy wykryto wyciek i zamknięto jedną pętlę chłodzenia, oprogramowanie może automatycznie rozłożyć obciążenie obliczeniowe na inne serwery, by zapobiec przegrzaniu tych chwilowo pozbawionych chłodzenia. Tego typu inteligentne reakcje są rozwijane przez liderów branży, aby nawet przy awarii chłodzenia zapewnić ciągłość usług.
Centra danych brzegowe (Edge)
Na tzw. brzegu sieci, w małych lokalizacjach przetwarzania danych (np. szafy IT w węzłach telekomunikacyjnych, mikro-centra danych przy stacjach bazowych 5G, czy lokalne serwerownie w fabrykach), wprowadzenie chłodzenia cieczą również staje się rzeczywistością – zwłaszcza tam, gdzie upakowanie sprzętu generuje duże ciepło. W środowiskach Edge głównym wyzwaniem jest brak stałego personelu na miejscu, dlatego zdalny monitoring i automatyka odgrywają kluczową rolę. System wykrywania wycieków w takim mini-centrum danych musi być niemal bezobsługowy i zdolny do powiadomienia centralnego zespołu nadzoru oddalonego o setki kilometrów. Popularnym rozwiązaniem jest integracja czujników wycieku z istniejącymi modułami telemetrycznymi – np. kontrolerami klimatyzacji lub zasilania – które już komunikują się z centralą przez Internet/VPN. Jeśli wykryty zostanie wyciek, alarm pojawia się na konsoli systemu zarządzania całą rozproszoną infrastrukturą (często jest to ujednolicone oprogramowanie DCIM obsługujące wiele mikro-lokalizacji). Kluczowe jest, by powiadomienie było natychmiastowe i trafiało do osób pełniących dyżur 24/7 – np. poprzez automatyczne SMSy lub alerty w aplikacji mobilnej. W centrach brzegowych stosuje się przeważnie kompaktowe zestawy czujników punktowych (np. jeden lub dwa detektory w podstawie szafy/racka, plus ew. czujnik w tacce ociekowej małego chłodzenia drzwiowego) połączone do sterownika IoT. Dodatkowo, ponieważ reakcja człowieka może być opóźniona, często implementuje się awaryjne wyłączanie – czujnik zalania może np. odciąć zasilanie serwera lub pompy wody w ciągu kilkudziesięciu sekund od wykrycia, by zapobiec poważnym szkodom (lepiej chwilowo utracić usługę niż zalać urządzenie i doprowadzić do długotrwałej awarii). Ponieważ edge datacenter często znajdują się w nietypowych miejscach (np. szafy w biurach, piwnicach, kontenerach na zewnątrz), specyficznym zagrożeniem mogą być czynniki środowiskowe – np. zamarznięcie pękniętej rurki zimą czy zalanie wskutek awarii instalacji wodociągowej budynku. Dlatego czujniki wycieku na brzegu nieraz spełniają podwójną funkcję: wykrywają zarówno wyciek chłodziwa, jak i zalanie wodą z otoczenia (np. woda gruntowa, deszczówka przedostająca się do kontenera). OCP wskazuje, że operatorzy Edge powinni bardzo rygorystycznie podchodzić do tych zagrożeń, bo w odległych lokalizacjach nawet drobna usterka może pozostać długo niezauważona – solidny system detekcji stanowi tu podstawę bezpieczeństwa.
Przykłady wdrożeń systemów wykrywania wycieków
Raport OCP prezentuje również studia przypadków ilustrujące praktyczne zastosowania opisanych technologii. Jednym z przytoczonych przykładów jest Sustainable Tropical Data Center Testbed (STDCT) na Narodowym Uniwersytecie Singapuru – nowatorska placówka badawcza będąca poligonem doświadczalnym dla technik chłodzenia cieczą w klimacie tropikalnym. W obiekcie tym zastosowano chłodzenie cieczą z rozprowadzeniem rur nad sufitem (overhead piping) nawet nad wrażliwymi systemami AI, jednak dzięki odpowiedniemu projektowi nie odnotowano incydentów zagrażających sprzętowi. Kluczem okazało się połączenie wielu najlepszych praktyk: bezpiecznej instalacji (rury poprowadzono nad korytarzami serwisowymi zgodnie z wytycznymi ASHRAE), detekcji wycieków (pod każdą potencjalną nieszczelnością zamontowano czujniki i korytka odprowadzające wodę) oraz skutecznego planu reagowania (opracowano procedury i redundancje pozwalające na szybkie przełączenie chłodzenia w razie awarii). Przypadek STDCT pokazuje, że nawet w wymagających warunkach (gorący, wilgotny klimat i eksperymentalne wysokogęste obciążenia AI) można bezpiecznie stosować ciecze w serwerowni, jeśli wdroży się kompleksowe strategie wykrywania i ograniczania skutków wycieków.
Innym przykładem, choć nie wymienionym z nazwy w raporcie, są implementacje u hyperskalerów – np. centra danych korporacji Meta (Facebook) z chłodzeniem bezpośrednim procesorów. W otwartych publikacjach można znaleźć informacje, że Meta w swoich obiektach stosuje szeroką gamę zabezpieczeń: od czujników wycieku w każdej szafie serwerowej po zaawansowane systemy zarządzania płynem zintegrowane z ich platformą monitoringu. W jednym z wystąpień inżynierowie Meta dzielili się, że incydentalne drobne wycieki (np. skropliny czy pojedyncze krople przy wymianie modułów) są natychmiast wykrywane i obsługiwane bez wpływu na ciągłość działania – co potwierdza skuteczność zaimplementowanych środków. Takie realne doświadczenia operatorów stanowią wartościowe case studies, które przenikają do wytycznych OCP i uwiarygadniają zalecane praktyki.
Rekomendacje OCP dla operatorów i integratorów
Raport OCP kończy się listą zaleceń, które mają pomóc operatorom centrów danych oraz integratorom infrastruktury IT we wdrażaniu skutecznych systemów wykrywania wycieków. Najważniejsze z tych rekomendacji można streścić następująco:
- Uwzględnij detekcję wycieków od początku projektu: Każdy system chłodzenia cieczą powinien od startu mieć zaplanowane czujniki wycieku i mechanizmy alarmowe. Integratorzy powinni projektować instalacje z myślą o „bezpiecznym uszkodzeniu” – czyli zakładać, że wyciek może nastąpić i przygotować infrastrukturę, by go od razu wychwyciła i zminimalizowała skutki.
- Dobierz odpowiedni typ czujników do zastosowania: OCP zaleca analizę rodzaju chłodziwa i środowiska pracy przy doborze sensorów. Dla wody i mieszanin glikolu dobrze sprawdzają się typowe czujniki rezystancyjne (kablowe lub punktowe). Jeśli używany jest płyn nieprzewodzący (np. fluoroketon, olej dielektryczny), należy zastosować czujniki pojemnościowe lub inny mechanizm reagujący na obecność cieczy (gdyż tradycyjne sensory rezystancyjne mogą nie zadziałać). W trudnych warunkach (np. bardzo niska temperatura, środowisko zewnętrzne) trzeba też dobrać czujniki o odpowiedniej trwałości i klasie szczelności.
- Pokryj czujnikami wszystkie krytyczne punkty i strefy: Każdy element, z którego może potencjalnie wyciec woda, powinien być monitorowany. Obejmuje to zarówno infrastrukturę wodną (rurociągi, pompy, wymienniki, złączki), jak i obszar IT (wnętrza szaf, tace ociekowe pod klimatyzatorami, podłoga techniczna w pobliżu sprzętu). W praktyce oznacza to łączenie różnych typów czujników – np. rope sensor wokół szaf plus punktowe detektory przy zaworach. Zaleca się też dodanie czujników w miejscach mniej oczywistych, jak przestrzenie pod podniesioną podłogą czy sufitem podwieszanym, gdzie może zbierać się wyciekająca ciecz.
- Zintegruj alarmy z systemami zarządzania (DCIM/BMS): Sam alarm lokalny to za mało – musi on dotrzeć do osób i systemów zdolnych zareagować. Dlatego czujniki/centralka powinny być podłączone do istniejącej platformy monitoringu centrum danych. OCP wskazuje, że w razie wycieku liczą się minuty, a nawet sekundy – pełna integracja pozwala automatycznie powiadomić obsługę (np. poprzez alert w DCIM) i jednocześnie np. zatrzymać dopływ chłodziwa czy wyłączyć zagrożone urządzenia. Warto przeprowadzić testy, czy alarm z czujnika faktycznie generuje wszystkie zaplanowane akcje (np. czy e-mail/SMS dociera do on-call engineer, czy BMS zamyka zawór itp.).
- Projektuj pod kątem ograniczania skutków wycieku: Oprócz samych czujników wdrażaj środki ochrony pasywnej – np. tace ociekowe pod sprzętem i na trasach rur, odpowiednie nachylenie podłóg (by woda spływała do czujnika zamiast rozlewać się szeroko), segmentację obwodów (małe objętości płynu w sekcji), a nawet ściany/kołnierze izolujące strefy mokre. Im mniejszy i bardziej kontrolowany potencjalny wyciek, tym łatwiej go wykryć i opanować.
- Stosuj komponenty wysokiej jakości i zapobiegaj awariom: Wielu problemów można uniknąć, wybierając na etapie budowy sprawdzone, certyfikowane elementy (złączki, uszczelki, węże odporne na wysokie ciśnienie itp.) oraz przestrzegając reżimu serwisowego. OCP kładzie nacisk na zapobieganie wyciekom poprzez dobór materiałów i właściwą eksploatację – zaleca się regularne inspekcje instalacji pod kątem oznak zużycia, dokręcanie połączeń gwintowanych, wymianę słabych ogniw przed ich awarią. Operatorzy powinni prowadzić rejestr przeglądów i incydentów, by uczyć się na bieżąco i ulepszać swoje systemy.
- Szkol personel i planuj procedury awaryjne: Czynnik ludzki nadal pozostaje bardzo ważny. Obsługa centrum danych musi wiedzieć, jak reagować gdy rozlegnie się alarm zalania – kto ma iść na miejsce, jakie wyłączniki użyć, kogo powiadomić. Dobrą praktyką jest opracowanie playbooka z instrukcjami na wypadek wycieku i regularne ćwiczenia (symulacje). Przy dynamicznym rozwoju technologii (np. nowych typach chłodzenia) warto dzielić się doświadczeniami w ramach społeczności OCP – tak aby cała branża uczyła się najlepszych sposobów radzenia sobie z wyzwaniami wycieków.
Dzięki powyższym wskazówkom, zawartym w raporcie OCP oraz popartym doświadczeniami czołowych operatorów, centra danych mogą bezpiecznie korzystać z wydajnych systemów chłodzenia cieczą. Wykrywanie wycieków wody – kiedyś postrzegane jako słaby punkt takiego rozwiązania – staje się dziś standardową funkcją projektową, dodającą kolejny poziom zabezpieczeń. Przy odpowiednim doborze technologii detekcji i wdrożeniu procedur, nawet najbardziej krytyczna serwerownia może czerpać korzyści z chłodzenia wodnego bez obaw, że „wyleje dziecko z kąpielą” – a społeczność OCP będzie nadal rozwijać otwarte standardy i dzielić się wiedzą, aby uczynić te rozwiązania jeszcze bardziej niezawodnymi.
Źródła: Raport OCP Leak Detection and Intervention oraz materiały powiązane, m.in. wytyczne ASHRAE i doświadczenia branżowe (Vertiv, DCD, LinkedIn).